unit-testing-4.4-寻找理想测试
zero4.4 In search of an ideal test
4.4 寻找理想测试
仅个人学习使用,支持正版。
书名:Unit Testing: Principles, Practices, and Patterns
Here are the four attributes of a good unit test once again:
我们再看一次优秀单元测试的四个属性:
- Protection against regressions
防止回归。 - Resistance to refactoring
抵抗重构。 - Fast feedback
快速反馈。 - Maintainability
可维护性。
These four attributes, when multiplied together, determine the value of a test. And by multiplied, I mean in a mathematical sense; that is, if a test gets zero in one of the attributes, its value turns to zero as well:
这四个属性相乘之后,决定了一个测试的价值。这里的“相乘”是数学意义上的相乘;也就是说,如果一个测试在其中某个属性上得分为零,它的整体价值也会变成零:
Value estimate = [0..1] * [0..1] * [0..1] * [0..1]TIP In order to be valuable, the test needs to score at least something in all four categories.
提示 一个测试要想有价值,必须在四个类别中都至少获得一定分数。
Of course, it’s impossible to measure these attributes precisely. There’s no code analysis tool you can plug a test into and get the exact numbers. But you can still evaluate the test pretty accurately to see where a test stands with regard to the four attributes. This evaluation, in turn, gives you the test’s value estimate, which you can use to decide whether to keep the test in the suite.
当然,精确衡量这些属性是不可能的。没有哪个代码分析工具可以让你输入一个测试,然后给出精确数字。但你仍然可以相当准确地评估一个测试在这四个属性上的表现。这个评估反过来会给出测试的价值估计,你可以据此决定是否把这个测试保留在测试套件中。
Remember, all code, including test code, is a liability. Set a fairly high threshold for the minimum required value, and only allow tests in the suite if they meet this threshold. A small number of highly valuable tests will do a much better job sustaining project growth than a large number of mediocre tests.
请记住,所有代码,包括测试代码,都是负债。你应该为最低价值设定一个相当高的门槛,只有满足这个门槛的测试才允许进入测试套件。少量高价值测试在支撑项目增长方面,会比大量平庸测试做得更好。
I’ll show some examples shortly. For now, let’s examine whether it’s possible to create an ideal test.
我马上会展示一些例子。现在,我们先看看是否可能创建一个理想测试。
4.4.1 Is it possible to create an ideal test?
4.4.1 是否可能创建理想测试?
An ideal test is a test that scores the maximum in all four attributes. If you take the minimum and maximum values as 0 and 1 for each of the attributes, an ideal test must get 1 in all of them.
理想测试是指在四个属性上都获得最高分的测试。如果把每个属性的最小值和最大值分别看作 0 和 1,那么理想测试必须在所有属性上都得到 1。
Unfortunately, it’s impossible to create such an ideal test. The reason is that the first three attributes—protection against regressions, resistance to refactoring, and fast feedback—are mutually exclusive. It’s impossible to maximize them all: you have to sacrifice one of the three in order to max out the remaining two.
遗憾的是,创建这样的理想测试是不可能的。原因在于,前三个属性——防止回归、抵抗重构和快速反馈——是相互排斥的。你不可能同时把它们全部最大化:为了最大化其中两个,你必须牺牲第三个。
Moreover, because of the multiplication principle (see the calculation of the value estimate in the previous section), it’s even trickier to keep the balance. You can’t just forgo one of the attributes in order to focus on the others. As I mentioned previously, a test that scores zero in one of the four categories is worthless. Therefore, you have to maximize these attributes in such a way that none of them is diminished too much. Let’s look at some examples of tests that aim at maximizing two out of three attributes at the expense of the third and, as a result, have a value that’s close to zero.
此外,由于乘法原则(见上一节中的价值估算公式),保持平衡会更加棘手。你不能为了专注于其他属性而完全放弃其中一个。正如前面所说,一个测试只要在四个类别中的任何一个得分为零,它就毫无价值。因此,你必须以一种不让任何属性被过度削弱的方式来最大化这些属性。下面我们看看一些测试例子:它们试图以牺牲第三个属性为代价,最大化三个属性中的两个,结果整体价值接近于零。
4.4.2 Extreme case #1: End-to-end tests
4.4.2 极端情况 #1:端到端测试
The first example is end-to-end tests. As you may remember from chapter 2, end-to-end tests look at the system from the end user’s perspective. They normally go through all of the system’s components, including the UI, database, and external applications.
第一个例子是端到端测试。你可能还记得第 2 章提到过,端到端测试会从最终用户的视角观察系统。它们通常会经过系统的所有组件,包括 UI、数据库和外部应用。
Since end-to-end tests exercise a lot of code, they provide the best protection against regressions. In fact, of all types of tests, end-to-end tests exercise the most code—both your code and the code you didn’t write but use in the project, such as external libraries, frameworks, and third-party applications.
由于端到端测试会执行大量代码,所以它们提供最强的回归防护。事实上,在所有测试类型中,端到端测试执行的代码最多——既包括你自己的代码,也包括你没有写但在项目中使用的代码,例如外部库、框架和第三方应用。
End-to-end tests are also immune to false positives and thus have a good resistance to refactoring. A refactoring, if done correctly, doesn’t change the system’s observable behavior and therefore doesn’t affect the end-to-end tests. That’s another advantage of such tests: they don’t impose any particular implementation. The only thing end-to-end tests look at is how a feature behaves from the end user’s point of view. They are as removed from implementation details as tests could possibly be.
端到端测试也不容易受到假阳性的影响,因此具备良好的抵抗重构能力。如果重构执行正确,它不会改变系统的可观察行为,因此不会影响端到端测试。这也是这类测试的另一个优点:它们不会强加某一种具体实现。端到端测试唯一关注的是某个功能从最终用户视角看起来如何。它们已经尽可能远离实现细节。
However, despite these benefits, end-to-end tests have a major drawback: they are slow. Any system that relies solely on such tests would have a hard time getting rapid feedback. And that is a deal-breaker for many development teams. This is why it’s pretty much impossible to cover your code base with only end-to-end tests.
然而,尽管有这些好处,端到端测试也有一个主要缺点:它们很慢。任何只依赖这类测试的系统,都很难获得快速反馈。对许多开发团队来说,这是一个无法接受的问题。这也是为什么几乎不可能只用端到端测试覆盖整个代码库。
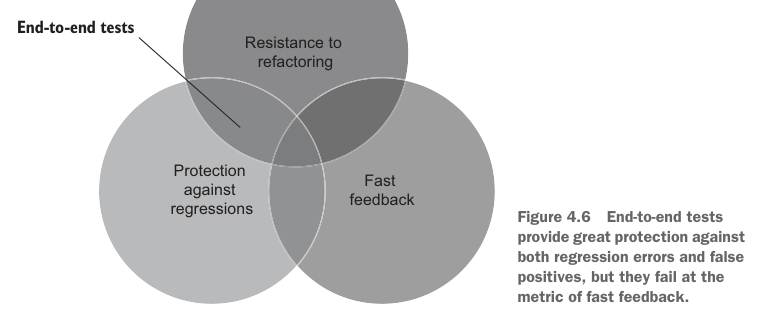
Figure 4.6 shows where end-to-end tests stand with regard to the first three unit testing metrics. Such tests provide great protection against both regression errors and false positives, but lack speed.
图 4.6 展示了端到端测试在前三个单元测试指标上的位置。这类测试既能很好地防止回归错误,也能很好地防止假阳性,但缺乏速度。
4.4.3 Extreme case #2: Trivial tests
4.4.3 极端情况 #2:琐碎测试
Another example of maximizing two out of three attributes at the expense of the third is a trivial test. Such tests cover a simple piece of code, something that is unlikely to break because it’s too trivial, as shown in the following listing.
另一个以牺牲第三个属性为代价来最大化三个属性中两个的例子,是琐碎测试。这类测试覆盖的是一小段非常简单的代码,因为过于简单,所以几乎不太可能出错,如下面的代码清单所示。
Listing 4.5 Trivial test covering a simple piece of code
public class User
{
public string Name { get; set; }
}
[Fact]
public void Test()
{
var sut = new User();
sut.Name = "John Smith";
Assert.Equal("John Smith", sut.Name);
}Unlike end-to-end tests, trivial tests do provide fast feedback—they run very quickly. They also have a fairly low chance of producing a false positive, so they have good resistance to refactoring. Trivial tests are unlikely to reveal any regressions, though, because there’s not much room for a mistake in the underlying code.
与端到端测试不同,琐碎测试确实能提供快速反馈——它们运行得非常快。它们产生假阳性的概率也相当低,所以具备良好的抵抗重构能力。不过,琐碎测试不太可能发现任何回归问题,因为底层代码没有多少出错空间。
Trivial tests taken to an extreme result in tautology tests. They don’t test anything because they are set up in such a way that they always pass or contain semantically meaningless assertions.
琐碎测试走到极端,就会变成同义反复式测试。它们并没有真正测试任何东西,因为它们被设置成总是通过,或者包含语义上毫无意义的断言。
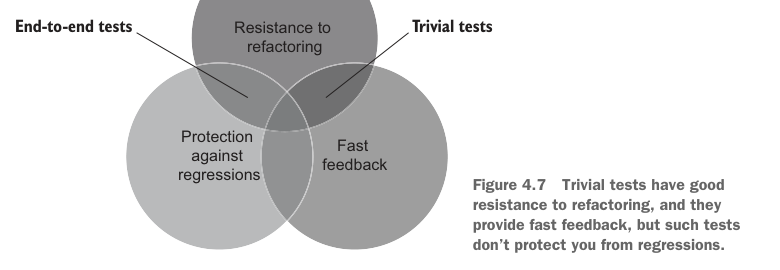
Figure 4.7 shows where trivial tests stand. They have good resistance to refactoring and provide fast feedback, but they don’t protect you from regressions.
图 4.7 展示了琐碎测试的位置。它们具备良好的抵抗重构能力,也能提供快速反馈,但无法保护你免受回归问题影响。
4.4.4 Extreme case #3: Brittle tests
4.4.4 极端情况 #3:脆弱测试
Similarly, it’s pretty easy to write a test that runs fast and has a good chance of catching a regression but does so with a lot of false positives. Such a test is called a brittle test: it can’t withstand a refactoring and will turn red regardless of whether the underlying functionality is broken.
类似地,写出一种运行快速、很有机会捕获回归问题、但同时产生大量假阳性的测试也很容易。这类测试称为脆弱测试:它无法承受重构,不管底层功能是否真的损坏,都会变红。
You already saw an example of a brittle test in listing 4.2. Here’s another one.
你已经在清单 4.2 中看到过脆弱测试的例子。下面是另一个例子。
Listing 4.6 Test verifying which SQL statement is executed
public class UserRepository
{
public User GetById(int id)
{
/* ... */
}
public string LastExecutedSqlStatement { get; set; }
}
[Fact]
public void GetById_executes_correct_SQL_code()
{
var sut = new UserRepository();
User user = sut.GetById(5);
Assert.Equal(
"SELECT * FROM dbo.[User] WHERE UserID = 5",
sut.LastExecutedSqlStatement);
}This test makes sure the UserRepository class generates a correct SQL statement when fetching a user from the database. Can this test catch a bug? It can. For example, a developer can mess up the SQL code generation and mistakenly use ID instead of UserID, and the test will point that out by raising a failure. But does this test have good resistance to refactoring? Absolutely not. Here are different variations of the SQL statement that lead to the same result:
这个测试确保 UserRepository 类在从数据库获取用户时会生成正确的 SQL 语句。这个测试能捕获缺陷吗?能。例如,开发者可能把 SQL 代码生成逻辑写错,错误地使用 ID 而不是 UserID,测试就会通过失败指出这个问题。但这个测试具备良好的抵抗重构能力吗?完全没有。下面这些 SQL 语句的不同变体都会得到相同结果:
SELECT * FROM dbo.[User] WHERE UserID = 5
SELECT * FROM dbo.User WHERE UserID = 5
SELECT UserID, Name, Email FROM dbo.[User] WHERE UserID = 5
SELECT * FROM dbo.[User] WHERE UserID = @UserIDThe test in listing 4.6 will turn red if you change the SQL script to any of these variations, even though the functionality itself will remain operational. This is once again an example of coupling the test to the SUT’s internal implementation details. The test is focusing on hows instead of whats and thus ingrains the SUT’s implementation details, preventing any further refactoring.
如果你把 SQL 脚本改成这些变体中的任何一个,清单 4.6 中的测试都会变红,即使功能本身仍然正常工作。这再次说明测试耦合到了 SUT 的内部实现细节。这个测试关注的是“如何做”,而不是“做什么”,因此把 SUT 的实现细节固化下来,阻止了进一步重构。
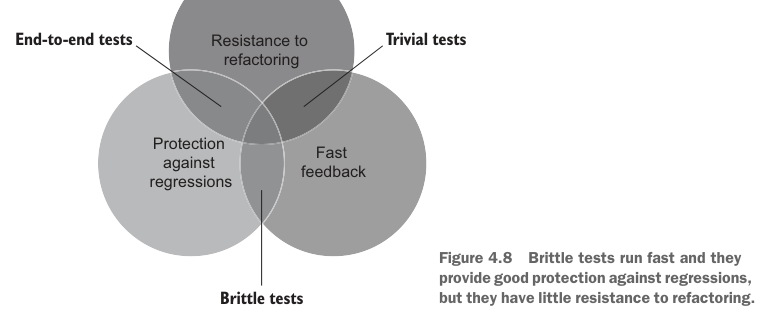
Figure 4.8 shows that brittle tests fall into the third bucket. Such tests run fast and provide good protection against regressions but have little resistance to refactoring.
图 4.8 显示,脆弱测试落在第三个类别中。这类测试运行快速,也能很好地防止回归,但几乎没有抵抗重构能力。
4.4.5 In search of an ideal test: The results
4.4.5 寻找理想测试:结论
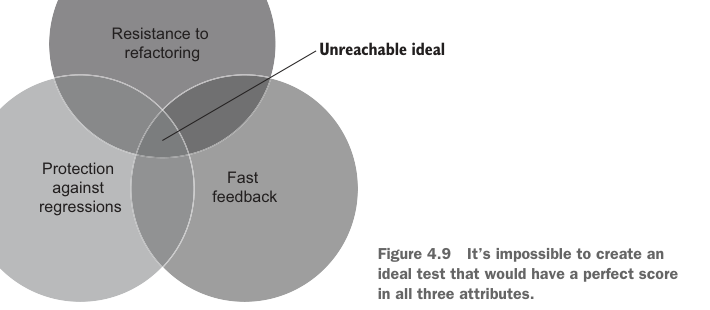
The first three attributes of a good unit test (protection against regressions, resistance to refactoring, and fast feedback) are mutually exclusive. While it’s quite easy to come up with a test that maximizes two out of these three attributes, you can only do that at the expense of the third. Still, such a test would have a close-to-zero value due to the multiplication rule. Unfortunately, it’s impossible to create an ideal test that has a perfect score in all three attributes.
优秀单元测试的前三个属性(防止回归、抵抗重构和快速反馈)是相互排斥的。设计一个最大化这三个属性中任意两个的测试相当容易,但你只能以牺牲第三个属性为代价做到这一点。即便如此,由于乘法规则,这样的测试价值也会接近于零。遗憾的是,创建一个在三个属性上都得满分的理想测试是不可能的。
The fourth attribute, maintainability, is not correlated to the first three, with the exception of end-to-end tests. End-to-end tests are normally larger in size because of the necessity to set up all the dependencies such tests reach out to. They also require additional effort to keep those dependencies operational. Hence end-to-end tests tend to be more expensive in terms of maintenance costs.
第四个属性,也就是可维护性,与前三个属性并不相关,端到端测试除外。端到端测试通常规模更大,因为必须设置它们会访问的所有依赖。它们还需要额外精力来保持这些依赖可用。因此,从维护成本角度看,端到端测试往往更昂贵。
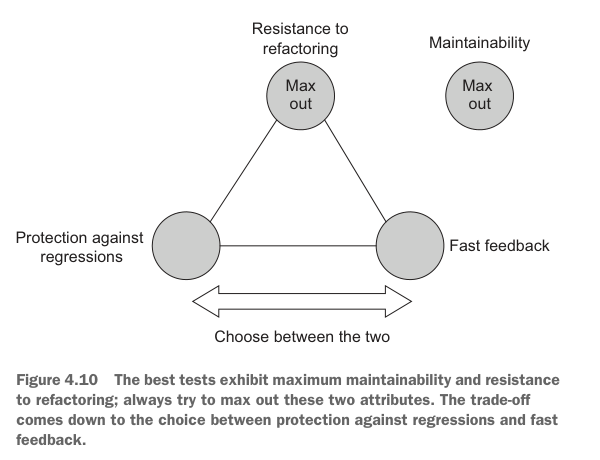
It’s hard to keep a balance between the attributes of a good test. A test can’t have the maximum score in each of the first three categories, and you also have to keep an eye on the maintainability aspect so the test remains reasonably short and simple. Therefore, you have to make trade-offs. Moreover, you should make those trade-offs in such a way that no particular attribute turns to zero. The sacrifices have to be partial and strategic.
在优秀测试的各个属性之间保持平衡很难。一个测试不可能在前三个类别中都拿到最高分,同时你还必须关注可维护性,让测试保持足够短小和简单。因此,你必须做取舍。而且,这些取舍应该以不让任何一个属性归零的方式进行。牺牲必须是局部的、战略性的。
What should those sacrifices look like? Because of the mutual exclusiveness of protection against regressions, resistance to refactoring, and fast feedback, you may think that the best strategy is to concede a little bit of each: just enough to make room for all three attributes.
这些牺牲应该是什么样的?由于防止回归、抵抗重构和快速反馈相互排斥,你可能会认为最好的策略是每个属性都稍微让步一点:刚好给三个属性都留出空间。
In reality, though, resistance to refactoring is non-negotiable. You should aim at gaining as much of it as you can, provided that your tests remain reasonably quick and you don’t resort to the exclusive use of end-to-end tests. The trade-off, then, comes down to the choice between how good your tests are at pointing out bugs and how fast they do that: that is, between protection against regressions and fast feedback. You can view this choice as a slider that can be freely moved between protection against regressions and fast feedback. The more you gain in one attribute, the more you lose on the other.
但实际上,抵抗重构是不可谈判的。只要你的测试仍然足够快,而且你没有完全依赖端到端测试,就应该尽可能获得更多抵抗重构能力。因此,真正的取舍变成了:你的测试发现缺陷的能力有多强,以及发现缺陷的速度有多快。也就是在防止回归和快速反馈之间进行选择。你可以把这个选择看成一个可以在防止回归和快速反馈之间自由移动的滑块。你在一个属性上获得越多,就会在另一个属性上失去越多。
The reason resistance to refactoring is non-negotiable is that whether a test possesses this attribute is mostly a binary choice: the test either has resistance to refactoring or it doesn’t. There are almost no intermediate stages in between. Thus you can’t concede just a little resistance to refactoring: you’ll have to lose it all. On the other hand, the metrics of protection against regressions and fast feedback are more malleable. You will see in the next section what kind of trade-offs are possible when you choose one over the other.
抵抗重构不可谈判的原因在于,一个测试是否具备这个属性基本上是二元选择:要么具备抵抗重构能力,要么不具备。中间几乎没有过渡状态。因此,你不能只牺牲“一点点”抵抗重构能力;你会失去全部。另一方面,防止回归和快速反馈这两个指标更有弹性。下一节会展示,当你在二者之间选择时,可以做出什么样的取舍。
TIP Eradicating brittleness (false positives) in tests is the first priority on the path to a robust test suite.
提示 在构建健壮测试套件的过程中,首要任务是消除测试脆弱性,也就是消除假阳性。
The CAP theorem
CAP 定理
The trade-off between the first three attributes of a good unit test is similar to the CAP theorem. The CAP theorem states that it is impossible for a distributed data store to simultaneously provide more than two of the following three guarantees:
优秀单元测试前三个属性之间的取舍,类似于 CAP 定理。CAP 定理指出,一个分布式数据存储不可能同时提供以下三个保证中的两个以上:
- Consistency, which means every read receives the most recent write or an error.
一致性,指每次读取都能获得最新写入结果,或者得到一个错误。 - Availability, which means every request receives a response (apart from outages that affect all nodes in the system).
可用性,指每个请求都能收到响应,但影响系统中所有节点的故障除外。 - Partition tolerance, which means the system continues to operate despite network partitioning (losing connection between network nodes).
分区容错性,指即使发生网络分区,也就是网络节点之间失去连接,系统仍然能够继续运行。
The similarity is two-fold:
二者的相似性体现在两个方面:
- First, there is the two-out-of-three trade-off.
第一,二者都有“三选二”的取舍。 - Second, the partition tolerance component in large-scale distributed systems is also non-negotiable. A large application such as, for example, the Amazon website can’t operate on a single machine. The option of preferring consistency and availability at the expense of partition tolerance simply isn’t on the table—Amazon has too much data to store on a single server, however big that server is.
第二,在大型分布式系统中,分区容错性同样是不可谈判的。比如 Amazon 网站这样的大型应用,不可能运行在单台机器上。以牺牲分区容错性为代价来优先选择一致性和可用性,这个选项根本不存在——Amazon 的数据太多,不可能存放在单台服务器上,无论这台服务器有多大。