unit-testing-4.1-深入理解优秀单元测试的四大支柱
zeroChapter 4.1 Diving into the four pillars of a good unit test
第 4.1 节 深入理解优秀单元测试的四大支柱
仅个人学习使用,支持正版。
书名:Unit Testing: Principles, Practices, and Patterns
A good unit test has the following four attributes:
一个好的单元测试具备以下四个属性:
- Protection against regressions
防止回归 - Resistance to refactoring
抵抗重构 - Fast feedback
快速反馈 - Maintainability
可维护性
These four attributes are foundational. You can use them to analyze any automated test, be it unit, integration, or end-to-end. Every such test exhibits some degree of each attribute. In this section, I define the first two attributes; and in section 4.2, I describe the intrinsic connection between them.
这四个属性是基础性的。你可以用它们分析任何自动化测试,无论是单元测试、集成测试,还是端到端测试。每一种这样的测试,都会在某种程度上体现这四个属性。本节会定义前两个属性;在 4.2 节中,我会说明它们之间的内在联系。
4.1.1 The first pillar: Protection against regressions
4.1.1 第一大支柱:防止回归
Let’s start with the first attribute of a good unit test: protection against regressions. As you know from chapter 1, a regression is a software bug. It’s when a feature stops working as intended after some code modification, usually after you roll out new functionality.
我们先从优秀单元测试的第一个属性开始:防止回归。正如你在第 1 章中了解到的,回归是一种软件缺陷。它指的是在修改代码之后,通常是在发布新功能之后,某个功能不再按预期工作。
Such regressions are annoying (to say the least), but that’s not the worst part about them. The worst part is that the more features you develop, the more chances there are that you’ll break one of those features with a new release. An unfortunate fact of programming life is that code is not an asset, it’s a liability. The larger the code base, the more exposure it has to potential bugs. That’s why it’s crucial to develop a good protection against regressions. Without such protection, you won’t be able to sustain the project growth in a long run—you’ll be buried under an ever-increasing number of bugs.
这些回归问题至少会让人很烦,但这还不是最糟糕的地方。最糟糕的是:你开发的功能越多,在新版本中破坏其中某个功能的概率就越高。编程世界里有一个不太令人愉快的事实:代码不是资产,而是负债。代码库越大,暴露在潜在缺陷下的面积就越大。这就是为什么建立良好的回归防护至关重要。没有这种保护,你就无法长期维持项目增长——你会被越来越多的缺陷淹没。
To evaluate how well a test scores on the metric of protecting against regressions, you need to take into account the following:
要评估一个测试在“防止回归”这个指标上的表现,需要考虑以下几点:
- The amount of code that is executed during the test
测试执行过程中覆盖了多少代码 - The complexity of that code
这些代码的复杂度 - The code’s domain significance
这些代码在领域中的重要性
Generally, the larger the amount of code that gets executed, the higher the chance that the test will reveal a regression. Of course, assuming that this test has a relevant set of assertions, you don’t want to merely execute the code. While it helps to know that this code runs without throwing exceptions, you also need to validate the outcome it produces.
一般来说,测试执行的代码越多,发现回归问题的概率就越高。当然,前提是这个测试具备相关的断言。你并不只是想“执行一下代码”而已。知道代码能够运行且不抛异常固然有用,但你还需要验证它产生的结果。
Note that it’s not only the amount of code that matters, but also its complexity and domain significance. Code that represents complex business logic is more important than boilerplate code—bugs in business-critical functionality are the most damaging.
注意,重要的不只是代码数量,还包括代码的复杂度和领域重要性。代表复杂业务逻辑的代码,比样板代码更重要——业务关键功能中的缺陷造成的破坏最大。
On the other hand, it’s rarely worthwhile to test trivial code. Such code is short and doesn’t contain a substantial amount of business logic. Tests that cover trivial code don’t have much of a chance of finding a regression error, because there’s not a lot of room for a mistake. An example of trivial code is a single-line property like this:
另一方面,测试琐碎代码通常并不值得。这类代码很短,也不包含实质性的业务逻辑。覆盖这种代码的测试发现回归错误的机会并不大,因为这里本来就没有多少出错空间。一个琐碎代码的例子,是下面这种单行属性:
public class User
{
public string Name { get; set; }
}Furthermore, in addition to your code, the code you didn’t write also counts: for example, libraries, frameworks, and any external systems used in the project. That code influences the working of your software almost as much as your own code. For the best protection, the test must include those libraries, frameworks, and external systems in the testing scope, in order to check that the assumptions your software makes about these dependencies are correct.
此外,除了你自己写的代码,那些不是你写的代码也要算进去:例如项目使用的库、框架,以及任何外部系统。这些代码对软件运行的影响几乎和你自己的代码一样大。为了获得最好的保护,测试必须把这些库、框架和外部系统纳入测试范围,以检查你的软件对这些依赖所做的假设是否正确。
TIP To maximize the metric of protection against regressions, the test needs to aim at exercising as much code as possible.
提示 要最大化“防止回归”这个指标,测试应该尽可能多地执行代码。
4.1.2 The second pillar: Resistance to refactoring
4.1.2 第二大支柱:抵抗重构
The second attribute of a good unit test is resistance to refactoring—the degree to which a test can sustain a refactoring of the underlying application code without turning red (failing).
优秀单元测试的第二个属性是抵抗重构,也就是当底层应用代码发生重构时,测试能够保持不变红(不失败)的程度。
DEFINITION Refactoring means changing existing code without modifying its observable behavior. The intention is usually to improve the code’s nonfunctional characteristics: increase readability and reduce complexity. Some examples of refactoring are renaming a method and extracting a piece of code into a new class.
定义 重构指的是在不改变代码可观察行为的前提下修改现有代码。其目的通常是改善代码的非功能性特征:提高可读性,降低复杂度。例如,重命名方法,或者把一段代码抽取到一个新类中。
Picture this situation. You developed a new feature, and everything works great. The feature itself is doing its job, and all the tests are passing. Now you decide to clean up the code. You do some refactoring here, a little bit of modification there, and everything looks even better than before. Except one thing—the tests are failing. You look more closely to see exactly what you broke with the refactoring, but it turns out that you didn’t break anything. The feature works perfectly, just as before. The problem is that the tests are written in such a way that they turn red with any modification of the underlying code. And they do that regardless of whether you actually break the functionality itself.
想象这样一种情况。你开发了一个新功能,一切运行良好。功能本身能正常工作,所有测试也都通过了。现在你决定清理一下代码。你这里做点重构,那里做点小修改,一切看起来都比之前更好了。只有一件事例外——测试失败了。你仔细查看,想知道自己到底在重构中破坏了什么,结果发现你什么也没破坏。功能和之前一样运行得很好。问题在于,这些测试的写法导致底层代码只要发生任何修改,它们就会变红。而且不管你是否真的破坏了功能,它们都会这样。
This situation is called a false positive. A false positive is a false alarm. It’s a result indicating that the test fails, although in reality, the functionality it covers works as intended. Such false positives usually take place when you refactor the code—when you modify the implementation but keep the observable behavior intact. Hence the name for this attribute of a good unit test: resistance to refactoring.
这种情况称为假阳性。假阳性就是误报。它表示测试失败了,但实际上该测试覆盖的功能仍然按预期工作。这样的假阳性通常发生在你重构代码时——也就是你修改了实现,但保持可观察行为不变。因此,优秀单元测试的这个属性被称为:抵抗重构。
To evaluate how well a test scores on the metric of resisting to refactoring, you need to look at how many false positives the test generates. The fewer, the better.
要评估一个测试在“抵抗重构”这个指标上的表现,需要看它产生多少假阳性。越少越好。
Why so much attention on false positives? Because they can have a devastating effect on your entire test suite. As you may recall from chapter 1, the goal of unit testing is to enable sustainable project growth. The mechanism by which the tests enable sustainable growth is that they allow you to add new features and conduct regular refactorings without introducing regressions. There are two specific benefits here:
为什么要如此关注假阳性?因为它们可能对整个测试套件产生毁灭性影响。你可能还记得第 1 章提到过,单元测试的目标是支持项目的可持续增长。测试支持可持续增长的机制在于:它们允许你添加新功能并定期重构,同时不引入回归问题。这里有两个具体收益:
- Tests provide an early warning when you break existing functionality. Thanks to such early warnings, you can fix an issue long before the faulty code is deployed to production, where dealing with it would require a significantly larger amount of effort.
当你破坏已有功能时,测试会提供早期预警。借助这种早期预警,你可以在有问题的代码部署到生产环境之前很久就修复问题;如果到了生产环境再处理,成本会高得多。 - You become confident that your code changes won’t lead to regressions. Without such confidence, you will be much more hesitant to refactor and much more likely to leave the code base to deteriorate.
你会确信自己的代码修改不会导致回归。没有这种信心,你就会更犹豫是否要重构,也更可能任由代码库逐渐恶化。
False positives interfere with both of these benefits:
假阳性会同时干扰这两个收益:
- If tests fail with no good reason, they dilute your ability and willingness to react to problems in code. Over time, you get accustomed to such failures and stop paying as much attention. After a while, you start ignoring legitimate failures, too, allowing them to slip into production.
如果测试无缘无故失败,它们会削弱你对代码问题做出反应的能力和意愿。随着时间推移,你会习惯这些失败,不再那么关注它们。再过一段时间,你也会开始忽略真正的失败,让它们溜进生产环境。 - On the other hand, when false positives are frequent, you slowly lose trust in the test suite. You no longer perceive it as a reliable safety net—the perception is diminished by false alarms. This lack of trust leads to fewer refactorings, because you try to reduce code changes to a minimum in order to avoid regressions.
另一方面,当假阳性频繁出现时,你会慢慢失去对测试套件的信任。你不再把它看作可靠的安全网——这种认知会被误报削弱。缺乏信任会导致重构减少,因为你会尽量把代码修改压到最低,以避免回归。
A story from the trenches
来自一线项目的故事
I once worked on a project with a rich history. The project wasn’t too old, maybe two or three years; but during that period of time, management significantly shifted the direction they wanted to go with the project, and development changed direction accordingly. During this change, a problem emerged: the code base accumulated large chunks of leftover code that no one dared to delete or refactor. The company no longer needed the features that code provided, but some parts of it were used in new functionality, so it was impossible to get rid of the old code completely.
我曾经参与过一个“历史包袱”很重的项目。这个项目并不算太老,可能只有两三年;但在这段时间里,管理层大幅调整了他们希望项目前进的方向,开发方向也随之改变。在这个变化过程中,一个问题出现了:代码库中积累了大量没人敢删除或重构的遗留代码。公司已经不再需要这些代码所提供的功能,但其中某些部分又被新功能使用着,所以无法彻底移除旧代码。
The project had good test coverage. But every time someone tried to refactor the old features and separate the bits that were still in use from everything else, the tests failed. And not just the old tests—they had been disabled long ago—but the new tests, too. Some of the failures were legitimate, but most were not—they were false positives.
这个项目的测试覆盖率不错。但每当有人尝试重构旧功能,把仍然在使用的部分和其他部分分离出来时,测试就会失败。不只是旧测试会失败——那些测试早就被禁用了——新测试也会失败。有些失败是合理的,但大多数并不是;它们是假阳性。
At first, the developers tried to deal with the test failures. However, since the vast majority of them were false alarms, the situation got to the point where the developers ignored such failures and disabled the failing tests. The prevailing attitude was, “If it’s because of that old chunk of code, just disable the test; we’ll look at it later.” Everything worked fine for a while—until a major bug slipped into production. One of the tests correctly identified the bug, but no one listened; the test was disabled along with all the others. After that accident, the developers stopped touching the old code entirely.
一开始,开发人员还试图处理这些测试失败。然而,由于绝大多数都是误报,情况逐渐发展到开发人员忽略这些失败,并禁用失败测试。普遍态度变成了:“如果是因为那块旧代码导致的,就先禁用测试吧,我们之后再看。”一段时间里一切似乎都正常——直到一个严重缺陷溜进了生产环境。其中一个测试正确识别出了这个缺陷,但没人理会;它和其他测试一起被禁用了。那次事故之后,开发人员完全停止触碰旧代码。
This story is typical of most projects with brittle tests. First, developers take test failures at face value and deal with them accordingly. After a while, people get tired of tests crying “wolf” all the time and start to ignore them more and more. Eventually, there comes a moment when a bunch of real bugs are released to production because developers ignored the failures along with all the false positives.
这个故事在大多数拥有脆弱测试的项目中都很典型。起初,开发人员会相信测试失败,并据此处理。过一段时间,人们会厌倦测试总是“狼来了”式地报警,于是越来越忽视它们。最终,某个时刻一批真正的缺陷被发布到了生产环境,因为开发人员把真正的失败和所有假阳性一起忽略了。
You don’t want to react to such a situation by ceasing all refactorings, though. The correct response is to re-evaluate the test suite and start reducing its brittleness. I cover this topic in chapter 7.
不过,你不应该通过停止所有重构来应对这种情况。正确的反应是重新评估测试套件,并开始降低它的脆弱性。这个主题我会在第 7 章中讨论。
4.1.3 What causes false positives?
4.1.3 什么会导致假阳性?
So, what causes false positives? And how can you avoid them?
那么,是什么导致了假阳性?又该如何避免它们?
The number of false positives a test produces is directly related to the way the test is structured. The more the test is coupled to the implementation details of the system under test (SUT), the more false alarms it generates. The only way to reduce the chance of getting a false positive is to decouple the test from those implementation details. You need to make sure the test verifies the end result the SUT delivers: its observable behavior, not the steps it takes to do that. Tests should approach SUT verification from the end user’s point of view and check only the outcome meaningful to that end user. Everything else must be disregarded (more on this topic in chapter 5).
一个测试产生多少假阳性,和这个测试的结构直接相关。测试和被测系统(SUT)的实现细节耦合得越紧,它产生的误报就越多。降低假阳性概率的唯一方法,是让测试与这些实现细节解耦。你需要确保测试验证的是 SUT 交付的最终结果:它的可观察行为,而不是它为了达成结果所采取的步骤。测试应该从最终用户的视角来验证 SUT,只检查对最终用户有意义的结果。其他一切都应忽略(第 5 章会进一步讨论这个话题)。
The best way to structure a test is to make it tell a story about the problem domain. Should such a test fail, that failure would mean there’s a disconnect between the story and the actual application behavior. It’s the only type of test failure that benefits you—such failures are always on point and help you quickly understand what went wrong. All other failures are just noise that steer your attention away from things that matter.
组织测试的最好方式,是让它讲述一个关于问题领域的故事。如果这样的测试失败了,失败就意味着这个故事和实际应用行为之间出现了不一致。这是唯一真正对你有益的测试失败类型——这种失败总是切中要害,并帮助你快速理解哪里出了问题。其他所有失败都只是噪音,会把你的注意力从真正重要的事情上带走。
Take a look at the following example. In it, the MessageRenderer class generates an HTML representation of a message containing a header, a body, and a footer.
来看下面这个例子。在这个例子中,MessageRenderer 类会为一条包含头部、正文和页脚的消息生成 HTML 表示。
Listing 4.1 Generating an HTML representation of a message
public class Message
{
public string Header { get; set; }
public string Body { get; set; }
public string Footer { get; set; }
}
public interface IRenderer
{
string Render(Message message);
}
public class MessageRenderer : IRenderer
{
public IReadOnlyList<IRenderer> SubRenderers { get; }
public MessageRenderer()
{
SubRenderers = new List<IRenderer>
{
new HeaderRenderer(),
new BodyRenderer(),
new FooterRenderer()
};
}
public string Render(Message message)
{
return SubRenderers
.Select(x => x.Render(message))
.Aggregate("", (str1, str2) => str1 + str2);
}
}The MessageRenderer class contains several sub-renderers to which it delegates the actual work on parts of the message. It then combines the result into an HTML document. The sub-renderers orchestrate the raw text with HTML tags. For example:
MessageRenderer 类包含多个子渲染器,并把消息不同部分的实际处理工作委托给它们。随后,它把结果组合成一个 HTML 文档。这些子渲染器会把原始文本和 HTML 标签组织在一起。例如:
public class BodyRenderer : IRenderer
{
public string Render(Message message)
{
return $"<b>{message.Body}</b>";
}
}How can MessageRenderer be tested? One possible approach is to analyze the algorithm this class follows.
应该如何测试 MessageRenderer?一种可能的方法,是分析这个类所遵循的算法。
Listing 4.2 Verifying that MessageRenderer has the correct structure
[Fact]
public void MessageRenderer_uses_correct_sub_renderers()
{
var sut = new MessageRenderer();
IReadOnlyList<IRenderer> renderers = sut.SubRenderers;
Assert.Equal(3, renderers.Count);
Assert.IsAssignableFrom<HeaderRenderer>(renderers[0]);
Assert.IsAssignableFrom<BodyRenderer>(renderers[1]);
Assert.IsAssignableFrom<FooterRenderer>(renderers[2]);
}This test checks to see if the sub-renderers are all of the expected types and appear in the correct order, which presumes that the way MessageRenderer processes messages must also be correct. The test might look good at first, but does it really verify MessageRenderer’s observable behavior? What if you rearrange the sub-renderers, or replace one of them with a new one? Will that lead to a bug?
这个测试会检查所有子渲染器是否都是预期类型,并且是否按正确顺序出现。它假设只要 MessageRenderer 处理消息的方式符合这个结构,那么它就一定是正确的。这个测试乍一看可能不错,但它真的验证了 MessageRenderer 的可观察行为吗?如果你重新排列子渲染器,或者用新的子渲染器替换其中一个,会导致缺陷吗?
Not necessarily. You could change a sub-renderer’s composition in such a way that the resulting HTML document remains the same. For example, you could replace BodyRenderer with a BoldRenderer, which does the same job as BodyRenderer. Or you could get rid of all the sub-renderers and implement the rendering directly in MessageRenderer.
不一定。你完全可以修改子渲染器的组合方式,同时让最终生成的 HTML 文档保持不变。例如,你可以用 BoldRenderer 替换 BodyRenderer,而它完成的工作和 BodyRenderer 一样。或者,你也可以完全移除所有子渲染器,直接在 MessageRenderer 中实现渲染。
Still, the test will turn red if you do any of that, even though the end result won’t change. That’s because the test couples to the SUT’s implementation details and not the outcome the SUT produces. This test inspects the algorithm and expects to see one particular implementation, without any consideration for equally applicable alternative implementations.
然而,只要你做了这些改动,测试就会变红,尽管最终结果没有变化。这是因为测试耦合到了 SUT 的实现细节,而不是 SUT 产生的结果。这个测试检查的是算法,并且期望看到某一种特定实现,却没有考虑其他同样可行的替代实现。
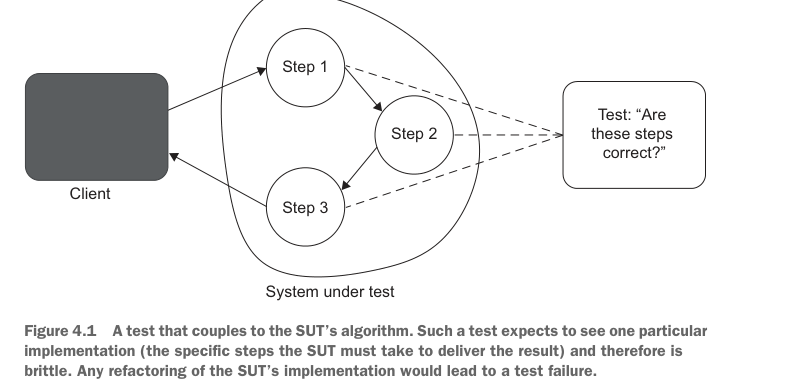
Any substantial refactoring of the MessageRenderer class would lead to a test failure. Mind you, the process of refactoring is changing the implementation without affecting the application’s observable behavior. And it’s precisely because the test is concerned with the implementation details that it turns red every time you change those details.
对 MessageRenderer 类进行任何实质性重构,都会导致测试失败。请注意,重构的过程就是在不影响应用程序可观察行为的前提下修改实现。也正是因为这个测试关心实现细节,所以每当你改变这些细节时,它都会变红。
Therefore, tests that couple to the SUT’s implementation details are not resistant to refactoring. Such tests exhibit all the shortcomings I described previously:
因此,耦合到 SUT 实现细节的测试并不抵抗重构。这类测试会表现出我前面描述过的所有缺点:
- They don’t provide an early warning in the event of regressions—you simply ignore those warnings due to little relevance.
当回归发生时,它们无法提供有效的早期预警——由于相关性太低,你会直接忽略这些警告。 - They hinder your ability and willingness to refactor. It’s no wonder—who would like to refactor, knowing that the tests can’t tell which way is up when it comes to finding bugs?
它们会阻碍你重构的能力和意愿。这并不奇怪——如果你知道测试在发现缺陷方面分不清方向,谁还愿意重构呢?
The next listing shows the most egregious example of brittleness in tests that I’ve ever encountered, in which the test reads the source code of the MessageRenderer class and compares it to the “correct” implementation.
下面的代码清单展示了我见过的最离谱的测试脆弱性示例:测试会读取 MessageRenderer 类的源代码,并把它和“正确”的实现进行比较。
Listing 4.3 Verifying the source code of the MessageRenderer class
[Fact]
public void MessageRenderer_is_implemented_correctly()
{
string sourceCode = File.ReadAllText(@"[path]\MessageRenderer.cs");
Assert.Equal(@"
public class MessageRenderer : IRenderer
{
public IReadOnlyList<<IRenderer> SubRenderers { get; }
public MessageRenderer()
{
SubRenderers = new List<<IRenderer>
{
new HeaderRenderer(),
new BodyRenderer(),
new FooterRenderer()
};
}
public string Render(Message message) { /* ... */ }
}", sourceCode);
}Of course, this test is just plain ridiculous; it will fail should you modify even the slightest detail in the MessageRenderer class. At the same time, it’s not that different from the test I brought up earlier. Both insist on a particular implementation without taking into consideration the SUT’s observable behavior. And both will turn red each time you change that implementation. Admittedly, though, the test in listing 4.3 will break more often than the one in listing 4.2.
当然,这个测试实在很荒唐;只要你修改了 MessageRenderer 类中哪怕最细微的细节,它都会失败。但与此同时,它和我前面提到的那个测试并没有本质区别。两者都坚持某一种特定实现,而没有考虑 SUT 的可观察行为。每当你修改这种实现时,它们都会变红。不过必须承认,清单 4.3 中的测试会比清单 4.2 中的测试更频繁地失败。
4.1.4 Aim at the end result instead of implementation details
4.1.4 面向最终结果,而不是实现细节
As I mentioned earlier, the only way to avoid brittleness in tests and increase their resistance to refactoring is to decouple them from the SUT’s implementation details—keep as much distance as possible between the test and the code’s inner workings, and instead aim at verifying the end result. Let’s do that: let’s refactor the test from listing 4.2 into something much less brittle.
正如前面所说,避免测试脆弱性并提升其抵抗重构能力的唯一方法,是让测试与 SUT 的实现细节解耦——让测试和代码内部工作机制之间保持尽可能远的距离,转而验证最终结果。我们现在就这么做:把清单 4.2 中的测试重构成一个不那么脆弱的版本。
To start off, you need to ask yourself the following question: What is the final outcome you get from MessageRenderer? Well, it’s the HTML representation of a message. And it’s the only thing that makes sense to check, since it’s the only observable result you get out of the class. As long as this HTML representation stays the same, there’s no need to worry about exactly how it’s generated. Such implementation details are irrelevant. The following code is the new version of the test.
首先,你需要问自己这样一个问题:从 MessageRenderer 得到的最终结果是什么?答案是:消息的 HTML 表示。而这也是唯一值得检查的东西,因为它是你从这个类中得到的唯一可观察结果。只要这个 HTML 表示保持不变,就没有必要关心它究竟是如何生成的。这样的实现细节并不相关。下面的代码是新版测试。
Listing 4.4 Verifying the outcome that MessageRenderer produces
[Fact]
public void Rendering_a_message()
{
var sut = new MessageRenderer();
var message = new Message
{
Header = "h",
Body = "b",
Footer = "f"
};
string html = sut.Render(message);
Assert.Equal("<h1>h</h1><b>b</b><i>f</i>", html);
}This test treats MessageRenderer as a black box and is only interested in its observable behavior. As a result, the test is much more resistant to refactoring—it doesn’t care what changes you make to the SUT as long as the HTML output remains the same.
这个测试把 MessageRenderer 当作黑盒,只关心它的可观察行为。因此,这个测试对重构的抵抗力强得多——只要 HTML 输出保持不变,它并不关心你对 SUT 做了什么修改。
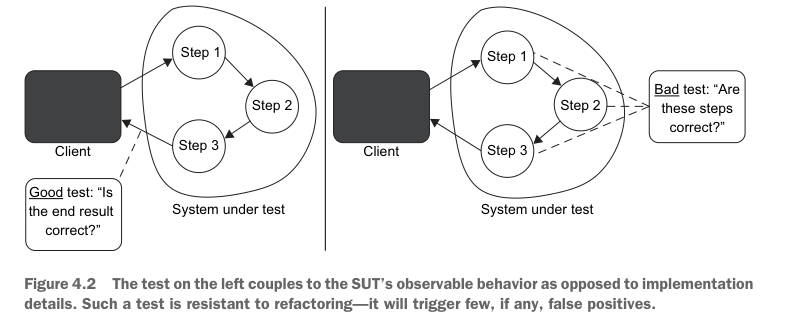
Notice the profound improvement in this test over the original version. It aligns itself with the business needs by verifying the only outcome meaningful to end users—how a message is displayed in the browser. Failures of such a test are always on point: they communicate a change in the application behavior that can affect the customer and thus should be brought to the developer’s attention. This test will produce few, if any, false positives.
注意,这个测试相比原始版本有了显著改进。它通过验证对最终用户唯一有意义的结果——消息在浏览器中的显示方式——与业务需求保持一致。这类测试的失败总是切中要害:它们传达的是应用程序行为发生了可能影响客户的变化,因此应该引起开发人员注意。这个测试即使产生假阳性,也会非常少。
Why few and not none at all? Because there could still be changes in MessageRenderer that would break the test. For example, you could introduce a new parameter in the Render() method, causing a compilation error. And technically, such an error counts as a false positive, too. After all, the test isn’t failing because of a change in the application’s behavior.
为什么是“非常少”,而不是“完全没有”?因为 MessageRenderer 仍然可能发生某些会破坏测试的变化。例如,你可能给 Render() 方法引入一个新参数,从而导致编译错误。从技术上讲,这种错误也算是假阳性。毕竟,测试失败并不是因为应用程序行为发生了变化。
But this kind of false positive is easy to fix. Just follow the compiler and add a new parameter to all tests that invoke the Render() method. The worse false positives are those that don’t lead to compilation errors. Such false positives are the hardest to deal with—they seem as though they point to a legitimate bug and require much more time to investigate.
但这种假阳性很容易修复。只要跟随编译器提示,在所有调用 Render() 方法的测试中添加新参数即可。更糟糕的假阳性,是那些不会导致编译错误的假阳性。这类假阳性最难处理——它们看起来像是在指向一个真正的缺陷,因此需要花更多时间调查。