wip-7.2
zero7.2 Refactoring toward valuable unit tests
7.2 重构为有价值的单元测试
In this section, I’ll show a comprehensive example of splitting overcomplicated code into algorithms and controllers. You saw a similar example in the previous chapter, where we talked about output-based testing and functional architecture. This time, I’ll generalize this approach to all enterprise-level applications, with the help of the Humble Object pattern. I’ll use this project not only in this chapter but also in the subsequent chapters of part 3.
本节中,我会展示一个完整示例,说明如何把过度复杂代码拆分为算法和控制器。你在上一章已经看过一个类似示例,当时我们讨论的是基于输出的测试和函数式架构。这一次,我会借助 Humble Object 模式,把这种方法推广到所有企业级应用。这个项目不仅会用于本章,也会用于第 3 部分后续章节。
7.2.1 Introducing a customer management system
7.2.1 引入一个客户管理系统
The sample project is a customer management system (CRM) that handles user registrations. All users are stored in a database. The system currently supports only one use case: changing a user’s email. There are three business rules involved in this operation:
示例项目是一个处理用户注册的客户管理系统(CRM)。所有用户都存储在数据库中。系统目前只支持一个用例:修改用户邮箱。这个操作涉及三条业务规则:
- If the user’s email belongs to the company’s domain, that user is marked as an employee. Otherwise, they are treated as a customer.
如果用户邮箱属于公司域名,则该用户被标记为员工。否则,该用户被视为客户。 - The system must track the number of employees in the company. If the user’s type changes from employee to customer, or vice versa, this number must change, too.
系统必须跟踪公司员工数量。如果用户类型从员工变为客户,或反过来从客户变为员工,这个数量也必须随之变化。 - When the email changes, the system must notify external systems by sending a message to a message bus.
当邮箱发生变化时,系统必须通过向消息总线发送消息来通知外部系统。
The following listing shows the initial implementation of the CRM system.
下面的代码清单展示了 CRM 系统的初始实现。

The User class changes a user email. Note that, for brevity, I omitted simple validations such as checks for email correctness and user existence in the database. Let’s analyze this implementation from the perspective of the types-of-code diagram.
User 类负责修改用户邮箱。注意,为了简洁起见,我省略了一些简单校验,例如检查邮箱格式是否正确,以及用户是否存在于数据库中。下面从代码类型图的角度分析这个实现。
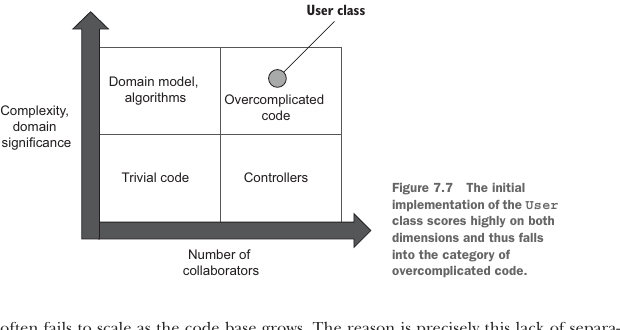
The code’s complexity is not too high. The ChangeEmail method contains only a couple of explicit decision-making points: whether to identify the user as an employee or a customer, and how to update the company’s number of employees. Despite being simple, these decisions are important: they are the application’s core business logic. Hence, the class scores highly on the complexity and domain significance dimension.
这段代码的复杂度并不算太高。ChangeEmail 方法只包含几个显式决策点:判断用户应识别为员工还是客户,以及如何更新公司员工数量。尽管这些决策很简单,但它们很重要:它们是应用程序的核心业务逻辑。因此,这个类在复杂度和领域重要性维度上得分很高。
On the other hand, the User class has four dependencies, two of which are explicit and the other two of which are implicit. The explicit dependencies are the userId and newEmail arguments. These are values, though, and thus don’t count toward the class’s number of collaborators. The implicit ones are Database and MessageBus. These two are out-of-process collaborators. As I mentioned earlier, out-of-process collaborators are a no-go for code with high domain significance. Hence, the User class scores highly on the collaborators dimension, which puts this class into the overcomplicated category (figure 7.7).
另一方面,User 类有四个依赖,其中两个是显式依赖,另外两个是隐式依赖。显式依赖是 userId 和 newEmail 参数。不过它们都是值,因此不计入这个类的协作者数量。隐式依赖是 Database 和 MessageBus。这两个都是进程外协作者。如前所述,对于具有高度领域重要性的代码来说,进程外协作者是禁区。因此,User 类在协作者维度上也得分很高,这使它落入过度复杂类别(图 7.7)。
This approach—when a domain class retrieves and persists itself to the database—is called the Active Record pattern. It works fine in simple or short-lived projects but often fails to scale as the code base grows. The reason is precisely this lack of separation between these two responsibilities: business logic and communication with out-of-process dependencies.
这种方式——领域类自己从数据库检索自己,并把自己持久化回数据库——称为 Active Record 模式。它在简单项目或短生命周期项目中运作良好,但随着代码库增长,往往难以扩展。原因正是它缺少对两种职责的分离:业务逻辑,以及与进程外依赖通信。
7.2.2 Take 1: Making implicit dependencies explicit
7.2.2 第一次尝试:让隐式依赖显式化
The usual approach to improve testability is to make implicit dependencies explicit: that is, introduce interfaces for Database and MessageBus, inject those interfaces into User, and then mock them in tests. This approach does help, and that’s exactly what we did in the previous chapter when we introduced the implementation with mocks for the audit system. However, it’s not enough.
改善可测试性的常见做法是让隐式依赖显式化:也就是说,为 Database 和 MessageBus 引入接口,把这些接口注入 User,然后在测试中 mock 它们。这种方法确实有帮助,上一章我们在为审计系统引入带 mock 的实现时,做的正是这件事。然而,这还不够。
From the perspective of the types-of-code diagram, it doesn’t matter if the domain model refers to out-of-process dependencies directly or via an interface. Such dependencies are still out-of-process; they are proxies to data that is not yet in memory. You still need to maintain complicated mock machinery in order to test such classes, which increases the tests’ maintenance costs. Moreover, using mocks for the database dependency would lead to test fragility (we’ll discuss this in the next chapter).
从代码类型图的角度看,领域模型是直接引用进程外依赖,还是通过接口引用进程外依赖,并没有本质区别。这些依赖仍然是进程外的;它们是尚未进入内存的数据的代理。为了测试这类类,你仍然需要维护复杂的 mock 机制,这会增加测试维护成本。此外,对数据库依赖使用 mock 会导致测试脆弱性(下一章会讨论这一点)。
Overall, it’s much cleaner for the domain model not to depend on out-of-process collaborators at all, directly or indirectly (via an interface). That’s what the hexagonal architecture advocates as well—the domain model shouldn’t be responsible for communications with external systems.
总体而言,领域模型完全不依赖进程外协作者会更清晰,无论是直接依赖,还是通过接口间接依赖。六边形架构倡导的也是这一点——领域模型不应该负责与外部系统通信。
7.2.3 Take 2: Introducing an application services layer
7.2.3 第二次尝试:引入应用服务层
To overcome the problem of the domain model directly communicating with external systems, we need to shift this responsibility to another class, a humble controller (an application service, in the hexagonal architecture taxonomy). As a general rule, domain classes should only depend on in-process dependencies, such as other domain classes, or plain values. Here’s what the first version of that application service looks like.
为了解决领域模型直接与外部系统通信的问题,我们需要把这个职责转移给另一个类:一个谦逊的控制器(在六边形架构分类中,也就是应用服务)。一般来说,领域类应该只依赖进程内依赖,例如其他领域类,或者普通值。下面是这个应用服务的第一个版本。
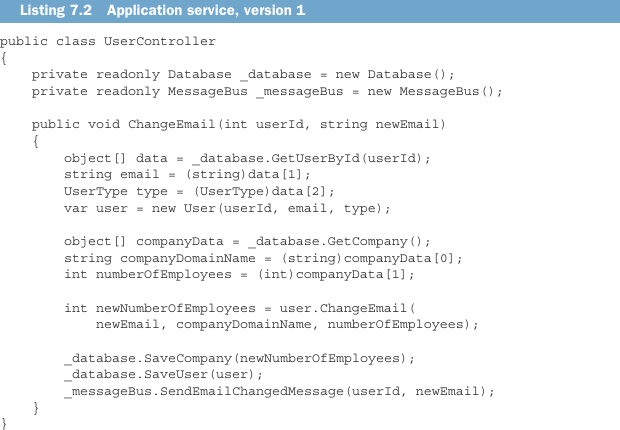
This is a good first try; the application service helped offload the work with out-of-process dependencies from the User class. But there are some issues with this implementation:
这是一个不错的第一次尝试;应用服务帮助 User 类卸下了与进程外依赖协作的工作。但这个实现仍然有一些问题:
- The out-of-process dependencies (Database and MessageBus) are instantiated directly, not injected. That’s going to be a problem for the integration tests we’ll be writing for this class.
进程外依赖(Database 和 MessageBus)是直接实例化的,而不是注入的。这会给我们后续为这个类编写集成测试带来问题。 - The controller reconstructs a User instance from the raw data it receives from the database. This is complex logic and thus shouldn’t belong to the application service, whose sole role is orchestration, not logic of any complexity or domain significance.
控制器会根据从数据库收到的原始数据重建 User 实例。这是复杂逻辑,因此不应该属于应用服务;应用服务唯一的角色是编排,而不是承载任何复杂逻辑或具有领域重要性的逻辑。 - The same is true for the company’s data. The other problem with that data is that User now returns an updated number of employees, which doesn’t look right. The number of company employees has nothing to do with a specific user. This responsibility should belong elsewhere.
公司数据也是如此。与这份数据相关的另一个问题是,User 现在会返回更新后的员工数量,这看起来不太对。公司员工数量与某个具体用户并没有直接关系。这个职责应该属于其他地方。 - The controller persists modified data and sends notifications to the message bus unconditionally, regardless of whether the new email is different than the previous one.
控制器会无条件持久化修改后的数据,并向消息总线发送通知,不管新邮箱是否与旧邮箱不同。
The User class has become quite easy to test because it no longer has to communicate with out-of-process dependencies. In fact, it has no collaborators whatsoever—out-of-process or not. Here’s the new version of User’s ChangeEmail method:
User 类现在变得相当容易测试,因为它不再需要与进程外依赖通信。事实上,它完全没有协作者——无论是不是进程外协作者。下面是 User 的 ChangeEmail 方法的新版本:
public int ChangeEmail(string newEmail,
string companyDomainName, int numberOfEmployees)
{
if (Email == newEmail)
return numberOfEmployees;
string emailDomain = newEmail.Split('@')[1];
bool isEmailCorporate = emailDomain == companyDomainName;
UserType newType = isEmailCorporate
? UserType.Employee
: UserType.Customer;
if (Type != newType)
{
int delta = newType == UserType.Employee ? 1 : -1;
int newNumber = numberOfEmployees + delta;
numberOfEmployees = newNumber;
}
Email = newEmail;
Type = newType;
return numberOfEmployees;
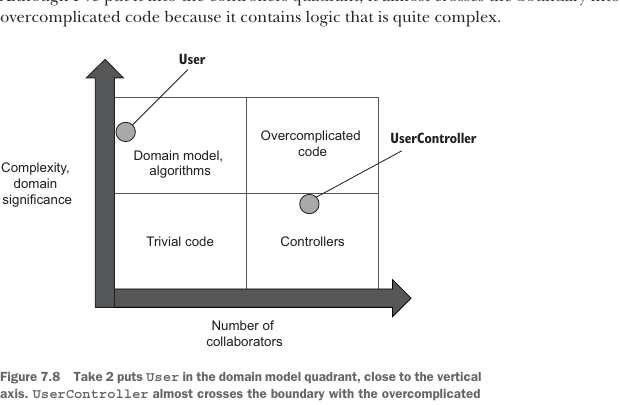
}Figure 7.8 shows where User and UserController currently stand in our diagram. User has moved to the domain model quadrant, close to the vertical axis, because it no longer has to deal with collaborators. UserController is more problematic. Although I’ve put it into the controllers quadrant, it almost crosses the boundary into overcomplicated code because it contains logic that is quite complex.
图 7.8 展示了 User 和 UserController 当前在图中的位置。User 已经移动到领域模型象限,并且靠近纵轴,因为它不再需要处理协作者。UserController 则更有问题。虽然我把它放到了控制器象限,但由于它包含相当复杂的逻辑,它几乎越过边界进入过度复杂代码区域。
7.2.4 Take 3: Removing complexity from the application service
7.2.4 第三次尝试:从应用服务中移除复杂度
To put UserController firmly into the controllers quadrant, we need to extract the reconstruction logic from it. If you use an object-relational mapping (ORM) library to map the database into the domain model, that would be a good place to which to attribute the reconstruction logic. Each ORM library has a dedicated place where you can specify how your database tables should be mapped to domain classes, such as attributes on top of those domain classes, XML files, or files with fluent mappings.
为了让 UserController 稳稳落在控制器象限中,我们需要从中提取出重建逻辑。如果你使用对象关系映射(ORM)库把数据库映射到领域模型,那么 ORM 就是放置这类重建逻辑的好地方。每个 ORM 库都有一个专门位置,让你指定数据库表应如何映射到领域类,例如领域类上的特性、XML 文件,或者 fluent mapping 文件。
If you don’t want to or can’t use an ORM, create a factory in the domain model that will instantiate the domain classes using raw database data. This factory can be a separate class or, for simpler cases, a static method in the existing domain classes. The reconstruction logic in our sample application is not too complicated, but it’s good to keep such things separated, so I’m putting it in a separate UserFactory class as shown in the following listing.
如果你不想或不能使用 ORM,可以在领域模型中创建一个工厂,用原始数据库数据实例化领域类。这个工厂可以是一个单独的类;在更简单的场景中,也可以是已有领域类里的静态方法。示例应用中的重建逻辑并不太复杂,但最好把这类东西分离出来,所以我把它放进单独的 UserFactory 类,如下面的代码清单所示。

This code is now fully isolated from all collaborators and therefore easily testable. Notice that I’ve put a safeguard in this method: a requirement to have at least three elements in the data array. Precondition is a simple custom class that throws an exception if the Boolean argument is false. The reason for this class is the more succinct code and the condition inversion: affirmative statements are more readable than negative ones. In our example, the data.Length >= 3 requirement reads better than
这段代码现在已经与所有协作者完全隔离,因此很容易测试。注意,我在这个方法中加入了一个保护措施:要求 data 数组至少包含三个元素。Precondition 是一个简单的自定义类;如果布尔参数为 false,它就会抛出异常。使用这个类的原因是代码更简洁,并且可以反转条件:肯定式陈述比否定式陈述更易读。在这个例子中,data.Length >= 3 这个要求读起来比下面这种写法更好:
if (data.Length < 3)
throw new Exception();Note that while this reconstruction logic is somewhat complex, it doesn’t have domain significance: it isn’t directly related to the client’s goal of changing the user email. It’s an example of the utility code I refer to in previous chapters.
注意,虽然这段重建逻辑有一定复杂度,但它没有领域重要性:它与客户修改用户邮箱的目标没有直接关系。这是我在前几章提到的工具代码的一个例子。
How is the reconstruction logic complex?
重建逻辑为什么算复杂?
How is the reconstruction logic complex, given that there’s only a single branching point in the UserFactory.Create() method? As I mentioned in chapter 1, there could be a lot of hidden branching points in the underlying libraries used by the code and thus a lot of potential for something to go wrong. This is exactly the case for the UserFactory.Create() method.
既然 UserFactory.Create() 方法中只有一个分支点,重建逻辑为什么还算复杂?正如我在第 1 章提到的,代码所使用的底层库中可能存在大量隐藏分支点,因此也有大量潜在出错点。UserFactory.Create() 方法正是这种情况。
Referring to an array element by index (data[0]) entails an internal decision made by the .NET Framework as to what data element to access. The same is true for the conversion from object to int or string. Internally, the .NET Framework decides whether to throw a cast exception or allow the conversion to proceed. All these hidden branches make the reconstruction logic test-worthy, despite the lack of decision points in it.
通过索引引用数组元素(data[0])意味着 .NET Framework 内部要做一个决策:访问哪个数据元素。从 object 转换为 int 或 string 也是如此。在内部,.NET Framework 会决定是抛出类型转换异常,还是允许转换继续。所有这些隐藏分支使重建逻辑值得测试,尽管它表面上缺少决策点。
7.2.5 Take 4: Introducing a new Company class
7.2.5 第四次尝试:引入新的 Company 类
Look at this code in the controller once again:
再次看看控制器中的这段代码:
object[] companyData = _database.GetCompany();
string companyDomainName = (string)companyData[0];
int numberOfEmployees = (int)companyData[1];
int newNumberOfEmployees = user.ChangeEmail(
newEmail, companyDomainName, numberOfEmployees);The awkwardness of returning an updated number of employees from User is a sign of a misplaced responsibility, which itself is a sign of a missing abstraction. To fix this, we need to introduce another domain class, Company, that bundles the company-related logic and data together, as shown in the following listing.
让 User 返回更新后的员工数量,这种别扭感说明职责放错了位置;而职责错位本身又说明缺少一个抽象。为了解决这个问题,我们需要引入另一个领域类 Company,把与公司相关的逻辑和数据绑定在一起,如下面的代码清单所示。

There are two methods in this class: ChangeNumberOfEmployees() and IsEmailCorporate(). These methods help adhere to the tell-don’t-ask principle I mentioned in chapter 5. This principle advocates for bundling together data and operations on that data. A User instance will tell the company to change its number of employees or figure out whether a particular email is corporate; it won’t ask for the raw data and do everything on its own.
这个类中有两个方法:ChangeNumberOfEmployees() 和 IsEmailCorporate()。这些方法有助于遵循我在第 5 章提到的“Tell, Don’t Ask”原则。这个原则主张把数据和作用于这些数据的操作绑定在一起。User 实例会告诉公司去修改员工数量,或者让公司判断某个邮箱是否属于公司邮箱;它不会索取原始数据,然后自己完成所有事情。
There’s also a new CompanyFactory class, which is responsible for the reconstruction of Company objects, similar to UserFactory. This is how the controller now looks.
现在还有一个新的 CompanyFactory 类,它负责重建 Company 对象,类似于 UserFactory。现在控制器如下所示。

And here’s the User class.
下面是 User 类。
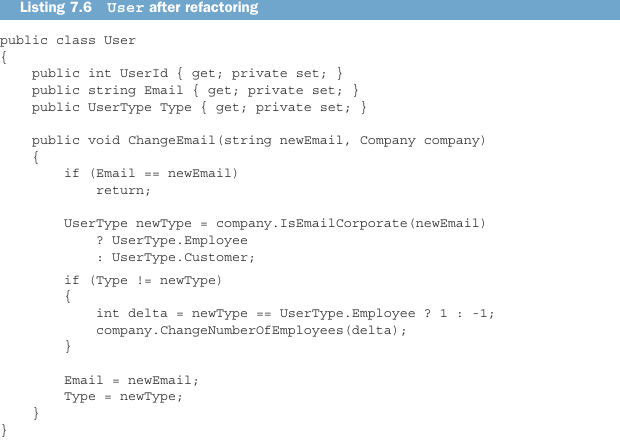
Notice how the removal of the misplaced responsibility made User much cleaner. Instead of operating on company data, it accepts a Company instance and delegates two important pieces of work to that instance: determining whether an email is corporate and changing the number of employees in the company.
注意,移除错位职责后,User 变得清爽得多。它不再操作公司数据,而是接收一个 Company 实例,并把两项重要工作委托给该实例:判断邮箱是否属于公司邮箱,以及修改公司员工数量。
Figure 7.9 shows where each class stands in the diagram. The factories and both domain classes reside in the domain model and algorithms quadrant. User has moved to the right because it now has one collaborator, Company, whereas previously it had none. That has made User less testable, but not much.
图 7.9 展示了每个类在图中的位置。工厂类和两个领域类都位于领域模型和算法象限。User 向右移动了一些,因为它现在有一个协作者 Company,而之前没有任何协作者。这让 User 的可测试性有所下降,但下降不多。
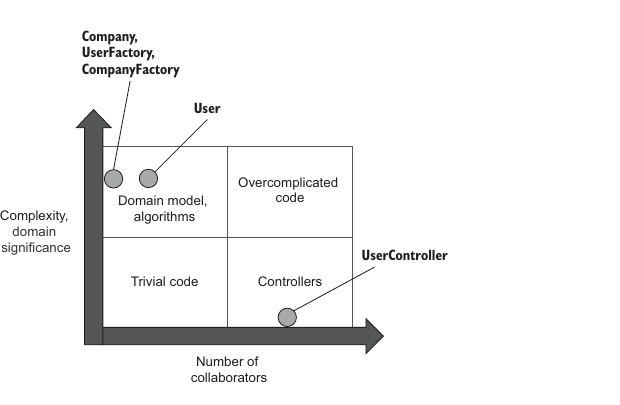
UserController now firmly stands in the controllers quadrant because all of its complexity has moved to the factories. The only thing this class is responsible for is gluing together all the collaborating parties.
UserController 现在稳稳处在控制器象限,因为它的所有复杂度都已经移动到了工厂类。这个类唯一负责的事情,就是把所有协作方粘合在一起。
Note the similarities between this implementation and the functional architecture from the previous chapter. Neither the functional core in the audit system nor the domain layer in this CRM (the User and Company classes) communicates with out-of-process dependencies. In both implementations, the application services layer is responsible for such communication: it gets the raw data from the filesystem or from the database, passes that data to stateless algorithms or the domain model, and then persists the results back to the data storage.
注意这个实现与上一章函数式架构之间的相似性。无论是审计系统中的函数式核心,还是这个 CRM 中的领域层(User 和 Company 类),都不与进程外依赖通信。在两个实现中,应用服务层都负责这种通信:它从文件系统或数据库获取原始数据,把这些数据传给无状态算法或领域模型,然后把结果持久化回数据存储。
The difference between the two implementations is in their treatment of side effects. The functional core doesn’t incur any side effects whatsoever. The CRM’s domain model does, but all those side effects remain inside the domain model in the form of the changed user email and the number of employees. The side effects only cross the domain model’s boundary when the controller persists the User and Company objects in the database.
这两个实现的区别在于它们对副作用的处理。函数式核心完全不产生任何副作用。CRM 的领域模型会产生副作用,但所有这些副作用都以已更改的用户邮箱和员工数量的形式留在领域模型内部。只有当控制器把 User 和 Company 对象持久化到数据库时,这些副作用才会跨越领域模型边界。
The fact that all side effects are contained in memory until the very last moment improves testability a lot. Your tests don’t need to examine out-of-process dependencies, nor do they need to resort to communication-based testing. All the verification can be done using output-based and state-based testing of objects in memory.
所有副作用都被保存在内存中直到最后一刻,这一点极大提升了可测试性。你的测试不需要检查进程外依赖,也不需要诉诸基于通信的测试。所有验证都可以通过对内存中对象进行基于输出的测试和基于状态的测试来完成。