wip-6.5
zero6.5 Understanding the drawbacks of functional architecture
6.5 理解函数式架构的缺点
Unfortunately, functional architecture isn’t always attainable. And even when it is, the maintainability benefits are often offset by a performance impact and increase in the size of the code base. In this section, we’ll explore the costs and the trade-offs attached to functional architecture.
遗憾的是,函数式架构并不总是可以实现。即便可以实现,它带来的可维护性收益也常常会被性能影响和代码库规模增加所抵消。本节中,我们会探讨函数式架构附带的成本和取舍。
6.5.1 Applicability of functional architecture
6.5.1 函数式架构的适用性
Functional architecture worked for our audit system because this system could gather all the inputs up front, before making a decision. Often, though, the execution flow is less straightforward. You might need to query additional data from an out-of-process dependency, based on an intermediate result of the decision-making process.
函数式架构适用于我们的审计系统,是因为这个系统可以在做出决策之前预先收集所有输入。不过,执行流程通常没有这么直接。你可能需要基于决策过程中的中间结果,从某个进程外依赖查询额外数据。
Here’s an example. Let’s say the audit system needs to check the visitor’s access level if the number of times they have visited during the last 24 hours exceeds some threshold. And let’s also assume that all visitors’ access levels are stored in a database. You can’t pass an IDatabase instance to AuditManager like this:
来看一个例子。假设审计系统需要在访客过去 24 小时内访问次数超过某个阈值时,检查该访客的访问级别。再假设所有访客的访问级别都存储在数据库中。你不能像这样把 IDatabase 实例传给 AuditManager:
public FileUpdate AddRecord(
FileContent[] files, string visitorName,
DateTime timeOfVisit, IDatabase database
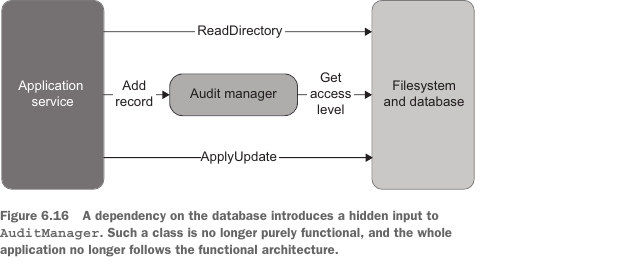
)Such an instance would introduce a hidden input to the AddRecord() method. This method would, therefore, cease to be a mathematical function (figure 6.16), which means you would no longer be able to apply output-based testing.
这样的实例会给 AddRecord() 方法引入隐藏输入。因此,该方法将不再是数学函数(图 6.16),这意味着你不再能够应用基于输出的测试。
There are two solutions in such a situation:
在这种情况下有两个解决方案:
- You can gather the visitor’s access level in the application service up front, along with the directory content.
你可以在应用服务中预先收集访客的访问级别,同时收集目录内容。 - You can introduce a new method such as
IsAccessLevelCheckRequired()inAuditManager. The application service would call this method beforeAddRecord(), and if it returned true, the service would get the access level from the database and pass it toAddRecord().
你可以在AuditManager中引入一个新方法,例如IsAccessLevelCheckRequired()。应用服务会在调用AddRecord()之前调用这个方法;如果它返回 true,服务就从数据库获取访问级别,并把它传给AddRecord()。
Both approaches have drawbacks. The first one concedes performance—it unconditionally queries the database, even in cases when the access level is not required. But this approach keeps the separation of business logic and communication with external systems fully intact: all decision-making resides in AuditManager as before. The second approach concedes a degree of that separation for performance gains: the decision as to whether to call the database now goes to the application service, not AuditManager.
两种方法都有缺点。第一种牺牲性能——即使在不需要访问级别的情况下,也会无条件查询数据库。但这种方法完整保留了业务逻辑与外部系统通信之间的分离:所有决策仍然像以前一样留在 AuditManager 中。第二种方法为了性能收益牺牲了一定程度的分离:是否调用数据库的决策现在交给应用服务,而不是 AuditManager。
Note that, unlike these two options, making the domain model (AuditManager) depend on the database isn’t a good idea. I’ll explain more about keeping the balance between performance and separation of concerns in the next two chapters.
请注意,与这两个选项不同,让领域模型(AuditManager)依赖数据库并不是好主意。我会在接下来的两章中进一步解释如何在性能与关注点分离之间保持平衡。
Collaborators vs. values
You may have noticed that AuditManager’s AddRecord() method has a dependency that’s not present in its signature: the _maxEntriesPerFile field. The audit manager refers to this field to make a decision to either append an existing audit file or create a new one.
协作者 vs. 值 你可能已经注意到,AuditManager 的 AddRecord() 方法有一个没有出现在其签名中的依赖:_maxEntriesPerFile 字段。审计管理器会引用这个字段,来决定是追加已有审计文件,还是创建新文件。
Although this dependency isn’t present among the method’s arguments, it’s not hidden. It can be derived from the class’s constructor signature. And because the _maxEntriesPerFile field is immutable, it stays the same between the class instantiation and the call to AddRecord(). In other words, that field is a value.
虽然这个依赖没有出现在方法参数中,但它不是隐藏的。它可以从类的构造函数签名推导出来。而且因为 _maxEntriesPerFile 字段是不可变的,它在类实例化与调用 AddRecord() 之间保持不变。换句话说,这个字段是一个值。
The situation with the IDatabase dependency is different because it’s a collaborator, not a value like _maxEntriesPerFile. As you may remember from chapter 2, a collaborator is a dependency that is one or the other of the following:
IDatabase 依赖的情况则不同,因为它是协作者,而不是像 _maxEntriesPerFile 那样的值。你可能还记得第 2 章,协作者是满足以下任一条件的依赖:
- Mutable (allows for modification of its state)
可变(允许修改自身状态)。 - A proxy to data that is not yet in memory (a shared dependency)
尚未进入内存的数据的代理(共享依赖)。
The IDatabase instance falls into the second category and, therefore, is a collaborator. It requires an additional call to an out-of-process dependency and thus precludes the use of output-based testing.
IDatabase 实例属于第二类,因此是协作者。它需要额外调用进程外依赖,因此排除了使用基于输出测试的可能。
NOTE A class from the functional core should work not with a collaborator, but with the product of its work, a value.
注意 函数式核心中的类不应该与协作者协作,而应该与协作者工作的产物——一个值——协作。
6.5.2 Performance drawbacks
6.5.2 性能缺点
The performance impact on the system as a whole is a common argument against functional architecture. Note that it’s not the performance of tests that suffers. The output-based tests we ended up with work as fast as the tests with mocks. It’s that the system itself now has to do more calls to out-of-process dependencies and becomes less performant. The initial version of the audit system didn’t read all files from the working directory, and neither did the version with mocks. But the final version does in order to comply with the read-decide-act approach.
对整个系统性能的影响,是反对函数式架构的常见理由。请注意,受影响的不是测试性能。我们最终得到的基于输出的测试,与使用 mock 的测试一样快。问题在于系统本身现在必须对进程外依赖进行更多调用,因此性能下降。审计系统的初始版本不会读取工作目录中的所有文件,mock 版本也不会。但最终版本为了遵循“读取-决策-执行”方法,会读取所有文件。
The choice between a functional architecture and a more traditional one is a trade-off between performance and code maintainability (both production and test code). In some systems where the performance impact is not as noticeable, it’s better to go with functional architecture for additional gains in maintainability. In others, you might need to make the opposite choice. There’s no one-size-fits-all solution.
在函数式架构与更传统架构之间选择,是性能与代码可维护性(包括生产代码和测试代码)之间的取舍。在某些性能影响不明显的系统中,选择函数式架构以获得额外可维护性收益会更好。在其他系统中,你可能需要做相反选择。没有一种放之四海而皆准的方案。
6.5.3 Increase in the code base size
6.5.3 代码库规模增加
The same is true for the size of the code base. Functional architecture requires a clear separation between the functional (immutable) core and the mutable shell. This necessitates additional coding initially, although it ultimately results in reduced code complexity and gains in maintainability.
代码库规模也是如此。函数式架构要求在函数式(不可变)核心与可变壳之间进行清晰分离。这在一开始需要编写额外代码,尽管最终会降低代码复杂度并提升可维护性。
Not all projects exhibit a high enough degree of complexity to justify such an initial investment, though. Some code bases aren’t that significant from a business perspective or are just plain too simple. It doesn’t make sense to use functional architecture in such projects because the initial investment will never pay off. Always apply functional architecture strategically, taking into account the complexity and importance of your system.
不过,并非所有项目都有足够高的复杂度来证明这种初始投入是合理的。有些代码库从业务角度并不那么重要,或者本身过于简单。在这类项目中使用函数式架构没有意义,因为初始投入永远无法回本。始终要战略性地应用函数式架构,考虑系统的复杂性和重要性。
Finally, don’t go for purity of the functional approach if that purity comes at too high a cost. In most projects, you won’t be able to make the domain model fully immutable and thus can’t rely solely on output-based tests, at least not when using an OOP language like C# or Java. In most cases, you’ll have a combination of output-based and state-based styles, with a small mix of communication-based tests, and that’s fine. The goal of this chapter is not to incite you to transition all your tests toward the output-based style; the goal is to transition as many of them as reasonably possible. The difference is subtle but important.
最后,如果函数式方法的纯粹性代价过高,就不要追求这种纯粹性。在大多数项目中,你无法让领域模型完全不可变,因此也不能只依赖基于输出的测试;至少在使用 C# 或 Java 这类面向对象语言时是如此。多数情况下,你会组合使用基于输出和基于状态的风格,并混入少量基于通信的测试,这完全没问题。本章的目标不是鼓动你把所有测试都转向基于输出的风格,而是尽可能合理地转移其中尽量多的测试。二者差异微妙但重要。