wip-1.3
zero1.3 Using coverage metrics to measure test suite quality
1.3 使用覆盖率指标衡量测试套件质量
In this section, I talk about the two most popular coverage metrics—code coverage and branch coverage—how to calculate them, how they’re used, and problems with them. I’ll show why it’s detrimental for programmers to aim at a particular coverage number and why you can’t just rely on coverage metrics to determine the quality of your test suite.
本节会讨论两种最流行的覆盖率指标:代码覆盖率和分支覆盖率。我们会看如何计算它们、如何使用它们,以及它们存在的问题。我会说明为什么程序员追求某个特定覆盖率数字是有害的,以及为什么你不能只依赖覆盖率指标来判断测试套件质量。
DEFINITION A coverage metric shows how much source code a test suite executes, from none to 100%.
定义 覆盖率指标表示测试套件执行了多少源代码,范围从完全没有到 100%。
There are different types of coverage metrics, and they’re often used to assess the quality of a test suite. The common belief is that the higher the coverage number, the better.
覆盖率指标有不同类型,它们经常被用来评估测试套件质量。常见观念是:覆盖率数字越高越好。
Unfortunately, it’s not that simple, and coverage metrics, while providing valuable feedback, can’t be used to effectively measure the quality of a test suite. It’s the same situation as with the ability to unit test the code: coverage metrics are a good negative indicator but a bad positive one.
不幸的是,事情并没有这么简单。覆盖率指标虽然能提供有价值的反馈,但不能被用来有效衡量测试套件质量。这和代码是否能被单元测试的情况一样:覆盖率指标是好的负向指标,却是糟糕的正向指标。
If a metric shows that there’s too little coverage in your code base—say, only 10%—that’s a good indication that you are not testing enough. But the reverse isn’t true: even 100% coverage isn’t a guarantee that you have a good-quality test suite. A test suite that provides high coverage can still be of poor quality.
如果某个指标显示你的代码库覆盖率太低,比如只有 10%,这很好地说明你的测试不够。但反过来并不成立:即使覆盖率达到 100%,也不能保证你拥有高质量测试套件。一个覆盖率很高的测试套件,仍然可能质量很差。
I already touched on why this is so—you can’t just throw random tests at your project with the hope those tests will improve the situation. But let’s discuss this problem in detail with respect to the code coverage metric.
我之前已经提到过原因:你不能只是随意往项目里添加测试,然后希望这些测试会改善局面。接下来我们围绕代码覆盖率指标详细讨论这个问题。
1.3.1 Understanding the code coverage metric
1.3.1 理解代码覆盖率指标
The first and most-used coverage metric is code coverage, also known as test coverage. This metric shows the ratio of the number of code lines executed by at least one test and the total number of lines in the production code base.
第一种也是最常用的覆盖率指标是代码覆盖率,也叫测试覆盖率。这个指标表示至少被一个测试执行过的代码行数,与生产代码库总代码行数之间的比例。

Let’s see an example to better understand how this works. Listing 1.1 shows an IsStringLong method and a test that covers it. The method determines whether a string provided to it as an input parameter is long (here, the definition of long is any string with the length greater than five characters). The test exercises the method using "abc" and checks that this string is not considered long.
我们来看一个例子,以便更好地理解它如何工作。清单 1.1 展示了一个 IsStringLong 方法以及覆盖它的一个测试。这个方法判断作为输入参数传入的字符串是否很长(这里“长”的定义是长度大于 5 个字符的任意字符串)。测试使用 "abc" 执行该方法,并检查这个字符串不应被视为长字符串。
Listing 1.1 A sample method partially covered by a test
清单 1.1 一个被测试部分覆盖的示例方法

It’s easy to calculate the code coverage here. The total number of lines in the method is five (curly braces count, too). The number of lines executed by the test is four—the test goes through all the code lines except for the return true; statement. This gives us 4/5 = 0.8 = 80% code coverage.
这里的代码覆盖率很容易计算。这个方法总共有 5 行(花括号也要算)。测试执行的行数是 4 行——除了 return true; 语句之外,测试走过了所有代码行。因此覆盖率是 4/5 = 0.8 = 80%。
Now, what if I refactor the method and inline the unnecessary if statement, like this?
现在,如果我重构这个方法,把不必要的 if 语句内联成这样,会发生什么?
public static bool IsStringLong(string input)
{
return input.Length > 5;
}
public void Test()
{
bool result = IsStringLong("abc");
Assert.Equal(false, result);
}Does the code coverage number change? Yes, it does. Because the test now exercises all three lines of code (the return statement plus two curly braces), the code coverage increases to 100%.
代码覆盖率数字会变化吗?会。因为测试现在执行了全部三行代码(return 语句加上两个花括号),代码覆盖率上升到了 100%。
But did I improve the test suite with this refactoring? Of course not. I just shuffled the code inside the method. The test still verifies the same number of possible outcomes.
但这次重构是否提升了测试套件质量?当然没有。我只是重新排列了方法内部的代码。测试验证的可能结果数量仍然相同。
This simple example shows how easy it is to game the coverage numbers. The more compact your code is, the better the code coverage metric becomes, because it only accounts for the raw line numbers. At the same time, squashing more code into less space doesn’t (and shouldn’t) change the value of the test suite or the maintainability of the underlying code base.
这个简单例子说明,操纵覆盖率数字是多么容易。代码越紧凑,代码覆盖率指标就越好看,因为它只统计原始行数。与此同时,把更多代码压缩到更少空间里,并不会(也不应该)改变测试套件的价值,或底层代码库的可维护性。
1.3.2 Understanding the branch coverage metric
1.3.2 理解分支覆盖率指标
Another coverage metric is called branch coverage. Branch coverage provides more precise results than code coverage because it helps cope with code coverage’s shortcomings. Instead of using the raw number of code lines, this metric focuses on control structures, such as if and switch statements. It shows how many of such control structures are traversed by at least one test in the suite.
另一种覆盖率指标叫分支覆盖率。分支覆盖率比代码覆盖率提供更精确的结果,因为它有助于弥补代码覆盖率的缺陷。它不使用原始代码行数,而是关注控制结构,例如 if 和 switch 语句。它显示测试套件中至少有一个测试遍历了多少这样的控制结构。

How is the branch coverage metric calculated? In the previous example, the IsStringLong method has two branches: one for the situation when the string is long and the other for when it is not. The test only exercises one of these branches. Therefore, branch coverage is 1/2 = 0.5 = 50%.
分支覆盖率如何计算?在前面的例子中,IsStringLong 方法有两个分支:一个对应字符串很长的情况,另一个对应字符串不长的情况。测试只执行了其中一个分支。因此分支覆盖率是 1/2 = 0.5 = 50%。
Figure 1.5 shows a helpful way to visualize this metric. You can represent all possible code paths as a graph of possible branch outcomes. The test covers only one of the two code paths.
图 1.5 展示了一种有助于理解该指标的可视化方式。你可以把所有可能代码路径表示为分支结果图。这个测试只覆盖了两条代码路径中的一条。
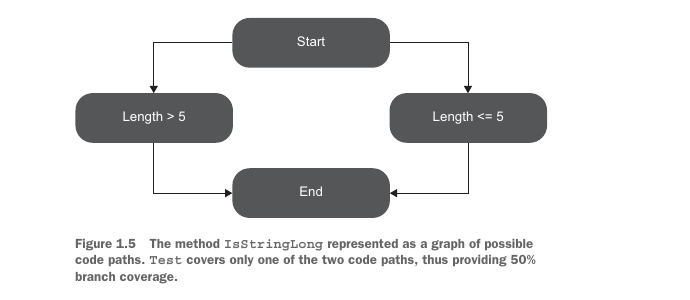
The branch coverage metric shows 50% in both versions of the method, regardless of whether the method uses an if statement or a single-line return expression. Thus, branch coverage is more resistant to code formatting and implementation shape than code coverage.
无论方法使用 if 语句,还是使用单行 return 表达式,分支覆盖率在两个版本中都会显示 50%。因此,与代码覆盖率相比,分支覆盖率更不容易受到代码格式和实现形式的影响。
1.3.3 Problems with coverage metrics
1.3.3 覆盖率指标的问题
Although branch coverage helps with some shortcomings of code coverage, it still has problems. In particular, coverage metrics don’t account for whether the tests verify all possible outcomes of the system under test.
尽管分支覆盖率有助于弥补代码覆盖率的一些缺陷,但它仍然存在问题。尤其是,覆盖率指标不会考虑测试是否验证了被测系统的所有可能结果。
YOU CAN’T GUARANTEE THAT THE TEST VERIFIES ALL THE POSSIBLE OUTCOMES
你无法保证测试验证了所有可能结果
Let’s say we modify IsStringLong so that it records the last result in a static property.
假设我们修改 IsStringLong,让它把上一次结果记录到一个静态属性中。
Listing 1.2 Version of IsStringLong that records the last result
清单 1.2 记录上一次结果的 IsStringLong 版本
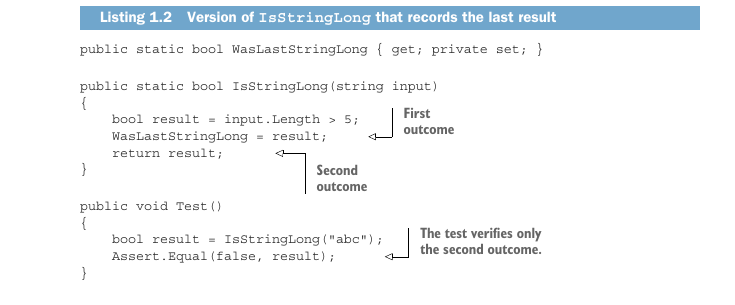
The IsStringLong method now has two outcomes: an explicit one, which is encoded by the return value; and an implicit one, which is the new value of the property. And in spite of not verifying the second, implicit outcome, the coverage metrics would still show the same results: 100% for the code coverage and 50% for the branch coverage. As you can see, the coverage metrics don’t guarantee that the underlying code is tested, only that it has been executed at some point.
IsStringLong 方法现在有两个结果:一个显式结果,由返回值表达;一个隐式结果,即属性的新值。尽管测试没有验证第二个隐式结果,覆盖率指标仍会显示相同结果:代码覆盖率 100%,分支覆盖率 50%。如你所见,覆盖率指标并不能保证底层代码被测试到了,只能保证它在某个时刻被执行过。
An extreme version of this situation with partially tested outcomes is assertion-free testing, which is when you write tests that don’t have any assertion statements in them whatsoever. Here’s an example of assertion-free testing.
这种“结果只被部分测试”的极端版本,是无断言测试,也就是你写出的测试中完全没有任何断言语句。下面是一个无断言测试的例子。
Listing 1.3 A test with no assertions always passes
清单 1.3 没有断言的测试总会通过

This test has both code and branch coverage metrics showing 100%. But at the same time, it is completely useless because it doesn’t verify anything.
这个测试的代码覆盖率和分支覆盖率都会显示 100%。但与此同时,它完全没用,因为它没有验证任何东西。
A story from the trenches
来自一线的故事
The concept of assertion-free testing might look like a dumb idea, but it does happen in the wild.
无断言测试这个概念看起来可能很愚蠢,但它确实会在现实中发生。
Years ago, I worked on a project where management imposed a strict requirement of having 100% code coverage for every project under development. This initiative had noble intentions. It was during the time when unit testing wasn’t as prevalent as it is today. Few people in the organization practiced it, and even fewer did unit testing consistently.
多年前,我参与过一个项目,当时管理层强制要求每个正在开发的项目都必须达到 100% 代码覆盖率。这个倡议的初衷是好的。那时单元测试还不像今天这么普及,组织里很少有人实践它,坚持进行单元测试的人就更少。
A group of developers had gone to a conference where many talks were devoted to unit testing. After returning, they decided to put their new knowledge into practice. Upper management supported them, and the great conversion to better programming techniques began. Internal presentations were given. New tools were installed. And, more importantly, a new company-wide rule was imposed: all development teams had to focus on writing tests exclusively until they reached the 100% code coverage mark. After they reached this goal, any code check-in that lowered the metric had to be rejected by the build systems.
一组开发人员参加了一场会议,会上很多演讲都围绕单元测试展开。回来之后,他们决定把新知识付诸实践。高层管理者支持他们,于是一场向更好编程技术转变的大运动开始了。内部分享举行了,新工具安装了。更重要的是,公司范围内推行了一条新规则:所有开发团队必须专注于写测试,直到达到 100% 代码覆盖率。达到这个目标之后,任何降低该指标的代码提交都必须被构建系统拒绝。
As you might guess, this didn’t play out well. Crushed by this severe limitation, developers started to seek ways to game the system. Naturally, many of them came to the same realization: if you wrap all tests with try/catch blocks and don’t introduce any assertions in them, those tests are guaranteed to pass. People started to mindlessly create tests for the sake of meeting the mandatory 100% coverage requirement.
你可能已经猜到了,事情发展得并不好。在这种严苛限制的压力下,开发人员开始寻找操纵系统的方法。很自然地,很多人得出了同样的结论:如果把所有测试都包在 try/catch 块中,并且不加入任何断言,这些测试就必定会通过。于是人们开始机械地创建测试,只是为了满足强制性的 100% 覆盖率要求。
Needless to say, those tests didn’t add any value to the projects. Moreover, they damaged the projects because of all the effort and time they steered away from productive activities, and because of the upkeep costs required to maintain the tests moving forward.
不用说,这些测试没有为项目增加任何价值。不仅如此,它们还损害了项目:一方面,它们把大量精力和时间从有生产力的活动中转移走;另一方面,后续维护这些测试还需要额外成本。
Eventually, the requirement was lowered to 90% and then to 80%; after some period of time, it was retracted altogether (for the better!).
最终,这个要求先被降低到 90%,然后降低到 80%;一段时间之后,它被彻底撤销了(这是好事!)。
But let’s say that you thoroughly verify each outcome of the code under test. Does this, in combination with the branch coverage metric, provide a reliable mechanism, which you can use to determine the quality of your test suite? Unfortunately, no.
但假设你已经彻底验证了被测代码的每个结果。那么,结合分支覆盖率指标,这是否就能提供一种可靠机制,用来判断测试套件质量?很遗憾,不能。
NO COVERAGE METRIC CAN TAKE INTO ACCOUNT CODE PATHS IN EXTERNAL LIBRARIES
没有任何覆盖率指标能够考虑外部库中的代码路径
The second problem with all coverage metrics is that they don’t take into account code paths that external libraries go through when the system under test calls methods on them. Let’s take the following example:
所有覆盖率指标的第二个问题是:当被测系统调用外部库方法时,它们不会考虑外部库内部经过的代码路径。我们来看下面这个例子:
public static int Parse(string input)
{
return int.Parse(input);
}
public void Test()
{
int result = Parse("5");
Assert.Equal(5, result);
}The branch coverage metric shows 100%, and the test verifies all components of the method’s outcome. It has a single such component anyway—the return value. At the same time, this test is nowhere near being exhaustive. It doesn’t take into account the code paths the .NET Framework’s int.Parse method may go through. And there are quite a number of code paths, even in this simple method.
分支覆盖率指标会显示 100%,而且测试验证了这个方法结果的所有组成部分。反正它也只有一个组成部分——返回值。与此同时,这个测试远远谈不上详尽。它没有考虑 .NET Framework 的 int.Parse 方法内部可能经过的代码路径。即使在这样一个简单方法中,代码路径也相当多。
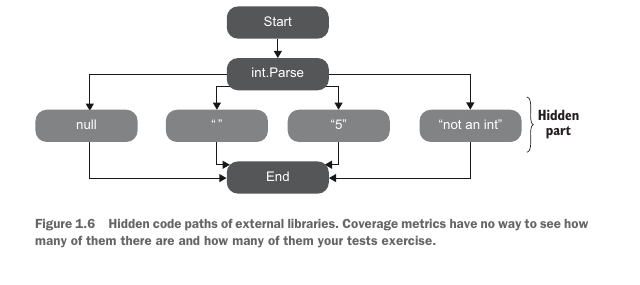
The built-in integer type has plenty of branches that are hidden from the test and that might lead to different results, should you change the method’s input parameter. Here are just a few possible arguments that can’t be transformed into an integer:
内置整数类型中有许多对测试隐藏的分支。如果你改变方法的输入参数,这些分支可能导致不同结果。下面只是几个无法转换成整数的可能参数:
- Null value
空值。 - An empty string
空字符串。 - “Not an int”
“不是整数”。 - A string that’s too large
过大的字符串。
You can fall into numerous edge cases, and there’s no way to see if your tests account for all of them.
你可能遇到大量边界情况,而且没有办法通过覆盖率指标看出测试是否覆盖了所有这些情况。
This is not to say that coverage metrics should take into account code paths in external libraries (they shouldn’t), but rather to show you that you can’t rely on those metrics to see how good or bad your unit tests are. Coverage metrics can’t possibly tell whether your tests are exhaustive; nor can they say if you have enough tests.
这并不是说覆盖率指标应该考虑外部库中的代码路径(它们不应该)。这里想说明的是,你不能依赖这些指标判断单元测试是好是坏。覆盖率指标不可能告诉你测试是否详尽,也不能告诉你测试是否足够。
1.3.4 Aiming at a particular coverage number
1.3.4 追求某个特定覆盖率数字
At this point, I hope you can see that relying on coverage metrics to determine the quality of your test suite is not enough. It can also lead to dangerous territory if you start making a specific coverage number a target, be it 100%, 90%, or even a moderate 70%. The best way to view a coverage metric is as an indicator, not a goal in and of itself.
到这里,我希望你已经看到,依赖覆盖率指标来判断测试套件质量是不够的。如果你开始把某个具体覆盖率数字当成目标,无论是 100%、90%,甚至只是中等的 70%,都会进入危险地带。看待覆盖率指标的最佳方式,是把它当成指标,而不是目标本身。
Think of a patient in a hospital. Their high temperature might indicate a fever and is a helpful observation. But the hospital shouldn’t make the proper temperature of this patient a goal to target by any means necessary. Otherwise, the hospital might end up with the quick and “efficient” solution of installing an air conditioner next to the patient and regulating their temperature by adjusting the amount of cold air flowing onto their skin. Of course, this approach doesn’t make any sense.
想象医院里的一位病人。体温过高可能表示发烧,这是一个有用的观察结果。但医院不应该把让病人体温达到正常值作为不惜一切代价追求的目标。否则,医院可能会采用一种快速而“高效”的方案:在病人旁边安装空调,通过调节吹到皮肤上的冷空气量来控制体温。当然,这种做法没有任何意义。
Likewise, targeting a specific coverage number creates a perverse incentive that goes against the goal of unit testing. Instead of focusing on testing the things that matter, people start to seek ways to attain this artificial target. Proper unit testing is difficult enough already. Imposing a mandatory coverage number only distracts developers from being mindful about what they test, and makes proper unit testing even harder to achieve.
同样,瞄准某个特定覆盖率数字会制造扭曲激励,违背单元测试的目标。人们不再关注测试真正重要的东西,而是开始寻找达成人工目标的方法。正确进行单元测试已经足够困难了。强制覆盖率数字只会分散开发者对“测试什么”的注意力,让正确的单元测试更难实现。
TIP It’s good to have a high level of coverage in core parts of your system. It’s bad to make this high level a requirement. The difference is subtle but critical.
提示 在系统核心部分拥有较高覆盖率是好事。把这种高覆盖率变成强制要求则是坏事。两者之间的差异微妙但关键。
Let me repeat myself: coverage metrics are a good negative indicator, but a bad positive one. Low coverage numbers—say, below 60%—are a certain sign of trouble. They mean there’s a lot of untested code in your code base. But high numbers don’t mean anything. Thus, measuring the code coverage should be only a first step on the way to a quality test suite.
让我重复一遍:覆盖率指标是好的负向指标,却是糟糕的正向指标。低覆盖率数字,比如低于 60%,明确表示存在问题。它意味着代码库中有大量未测试代码。但高覆盖率数字并不说明什么。因此,度量代码覆盖率只能是通往高质量测试套件的第一步。